WHAT THE STUDY ACTUALLY MEASURED
The Harvard-led research team tested OpenAI's o1 model across a range of clinical scenarios: published patient vignettes drawn from medical literature, and — crucially — real electronic health records from the emergency department of a Boston teaching hospital. The inclusion of real ER cases distinguishes this from the many prior AI-in-medicine studies that used curated or idealised inputs. These were actual patients who presented at an actual emergency department, with the messy, incomplete, sometimes contradictory record-keeping that characterises real clinical environments.
Physicians at multiple levels of experience and training participated — from residents to attending physicians with years of emergency medicine practice. Each was given the same text-based patient records and asked to arrive at a diagnosis and management plan. The AI received the same inputs. Evaluators scored responses on whether the diagnosis was exact or near-exact, and on the quality of the management plan at each stage of the clinical assessment: initial triage, differential formulation, and final working diagnosis.
The study was published in Science, which sets it apart from the volume of AI-in-medicine preprints that circulate without peer review. The journal's review process and the Harvard institutional context mean the methodology has been scrutinised more rigorously than most work in this space. That doesn't make the findings unquestionable, but it does mean the obvious objections have been considered and addressed in the study design to a degree that warrants taking the results seriously.
THE NUMBERS THAT MATTER
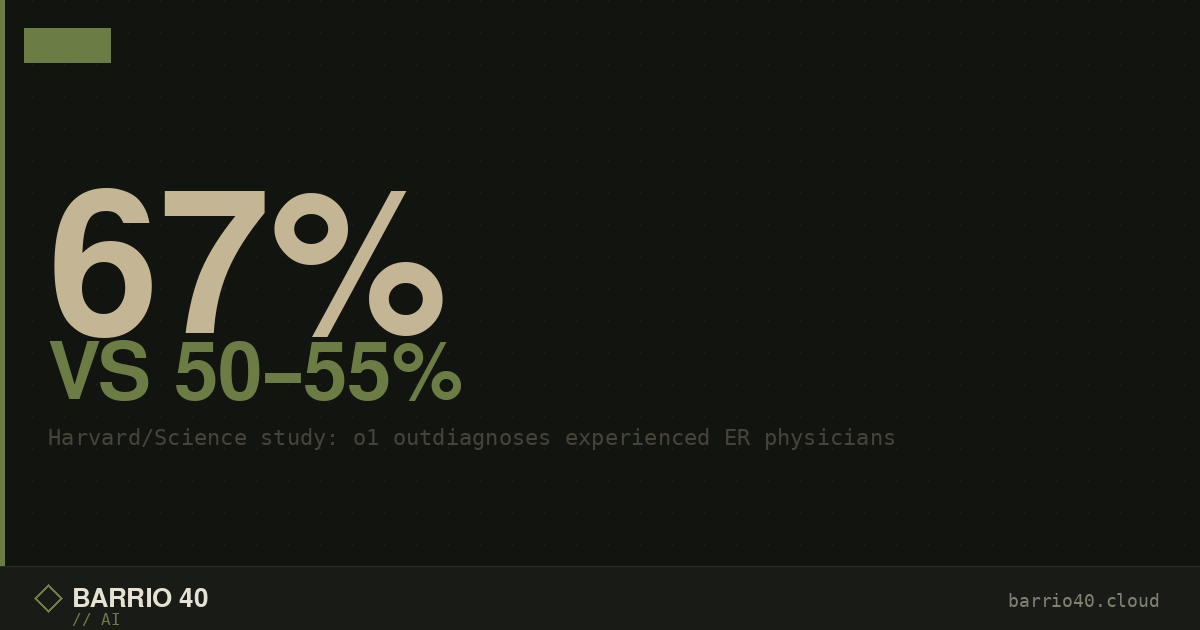
On real-world emergency department cases, two groups of physicians arrived at exact or near-exact diagnoses in 50% and 55% of cases respectively. The o1 model scored 67%. That 12-to-17 percentage point gap is large enough to be clinically meaningful — in emergency medicine, a missed diagnosis is not an abstract statistical failure. It is a patient who is sent home with the wrong treatment, or not treated at all for a condition that was present and detectable from the available information.
The AI also outperformed physicians across each stage of the ER assessment, not just the final diagnosis. At triage — the initial stage where the patient has just arrived and the information available is at its thinnest — the performance advantage was most pronounced. This is the finding that most challenges the intuitive assumption that AI would perform better as it accumulates more context. The model's reasoning is apparently better calibrated to uncertainty than human clinicians working under the same information constraints.
The management plan quality results tracked alongside the diagnostic accuracy results. An AI that diagnosed more accurately also tended to recommend more appropriate next steps. This suggests the performance advantage is not a narrow capability in pattern-matching diagnosis codes to symptom clusters — it reflects something more like coherent clinical reasoning across the full assessment workflow, at least within the constraints of the study design.
THE TRIAGE FINDING IS THE SURPRISING ONE
Seasoned emergency physicians are typically most confident in their pattern recognition at triage — the rapid, gestalt assessment of a patient that experienced clinicians develop over years of practice. "Sick or not sick" is a phrase used in emergency medicine to describe the near-instantaneous judgment that precedes formal assessment, and it is considered a distinctively human skill developed through accumulated exposure to thousands of patients. The study found the AI was particularly good at exactly this stage.
One interpretation is that the pattern recognition underlying triage judgment is more computable than clinical intuition has suggested. The cues that experienced physicians process rapidly — symptom combinations, vital sign patterns, complaint histories — may be more systematically learnable from training data than the subjective experience of practising medicine implied. A model trained on vast quantities of medical text, case records, and clinical literature may have learned correlations that individual physicians develop only through decades of practice, and learned them at a scale no individual career could provide.
Another interpretation is that triage in text-based settings is not the same as triage in person. The physicians in the study were working from the same text records as the AI, which strips out the visual and verbal cues — patient appearance, tone of voice, the way someone describes their pain — that real triage integrates. If those cues are important, the study may be measuring performance at a text-only proxy for triage rather than triage itself. Both interpretations are worth holding simultaneously, because the study's design cannot distinguish between them.
WHAT TEXT-ONLY MEANS
The most significant limitation of the study is also the most important one for understanding what the results actually prove: everything happened in text. The AI received electronic health records. The physicians received electronic health records. No one examined a patient. No one observed breathing rate, skin colour, or the subtle signs of distress that experienced emergency physicians describe as central to their assessment. No one listened to a chest, palpated an abdomen, or asked a follow-up question based on the patient's response.
This matters because clinical medicine is not primarily a text-processing task. Electronic health records are a documentation artefact — they capture what clinicians thought was worth writing down, which is a filtered and structured representation of a patient encounter rather than the encounter itself. A physician working from EHR records alone is already operating with significant information loss compared to seeing the patient. The study measures AI performance in a text-only setting and physician performance in a text-only setting, which is a fair comparison between the two but not a full comparison of AI versus clinical practice.
The researchers are clear about this. They describe the study as measuring performance on "the reasoning tasks of a physician" — specifically the reasoning that operates on documented information — rather than the full scope of clinical practice. That framing is accurate and honest. It means the result should be read as: AI reasoning models can outperform physicians at text-based clinical reasoning, which is a real and important finding. It should not be read as: AI can replace emergency room physicians, which the study does not claim and does not support.
WHAT THIS CHANGES AND WHAT IT DOESN'T
The honest answer is that this study changes the terrain of a debate rather than settling it. For years, AI-in-medicine optimists and sceptics have been arguing about whether language models would ever match clinical performance in realistic settings. The answer from this study, in the specific domain of text-based diagnostic reasoning on real ER cases, is: yes, they already do, and by a meaningful margin. That is a significant empirical contribution that makes certain sceptical positions harder to hold.
What it doesn't change is the question of deployment. A model that outperforms physicians at text-based reasoning in a controlled study still needs to be integrated into clinical workflows, validated across different patient populations and hospital systems, evaluated for failure modes that don't appear in study conditions, and governed by accountability structures that don't yet exist. The gap between "this model performs well in a study" and "this model is safely deployed in emergency departments" is substantial and not primarily a technical gap. It is a regulatory, institutional, and liability gap that no benchmark can bridge.
The researchers' framing — AI as a partner to physicians rather than a replacement — is the appropriate one, and it is also strategically useful. The finding that an AI model outperforms physicians at triage is more actionable as "AI flags the cases that text-based triage would miss, which physicians then assess with full clinical access" than as "AI replaces the triage nurse." The former is a system that uses the AI's demonstrated strength while preserving the physician's access to information the AI cannot see. It is also a system that is legible to regulators, defensible to liability insurers, and adoptable by clinical institutions — all of which matter more than the benchmark number for whether this technology actually helps patients.